
Python实例1--文本进度条
文本进度条的分析
1、采用字符串方式打印可以动态变化的文本进度条
2、进度条需要能在一行中逐渐变化
3、采用sleep()模拟一个持续的进度
文本进度条框架
1 | import time |
执行结果如下图
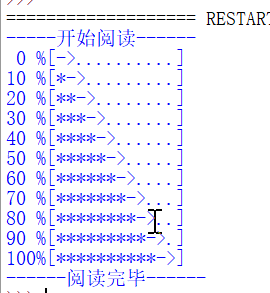
我们可以看到这个文本进度条包括百分比,”开始阅读”及”阅读完毕”的字眼,以及剩余阅读部分的进度条格式。
分析代码
1 | import time |
我们先引入一个time库,整体用sleep函数,来生成一个持续不断的时间。
1 | print("-----开始阅读------") |
我们打印了开始阅读和阅读完毕的字眼,为了使看起来更加美观,引入了减号”-“,字体居中。
1 | scale = 10 |
scale指的是文本进度条的大概宽度
1 | for i in range(scale+1): |
for循环,for i in range 这样的表达方式,表示遍历range() 对象。之所以称为遍历循环,是因为for语句的循环执行次数是根据遍历结构中元素的个数确定的。遍历循环可以简单的理解为从遍历结构中逐一提取元素,放入循环变量中,对于每个所提取的元素执行一次循环体语句,当遍历结构中所有的元素都被访问遍了,遍历循环就正常结束。
放到进度条中,可以理解为,每经过一个循环,计算机完成一个任务,打印一个进度条,计算机再完成一个任务,再打印一个进度条。直到进度条百分百,即完成了任务,打印出“阅读完毕”。
1 | a = '*'*i |
定义a,字符*与循环变量i的乘积
(在字符串中学过,字符串与整数的乘积表示字符串被复制的次数)
因此,a表示星号*被复制的次数,而星号指当前的百分比所表达的信息。
1 | b = '.'*(scale - i) |
定义b,用.表示,与当前剩余的进度条的笔记之间的乘积。
1 | c = (i/scale)*100 |
c指的是我们输出与当前进度条和进度相关的百分比
1 | print("{:^3.0f}%[{}->{}]".format(c,a,b)) |
前面我们学过,百分比%和括号{},可以表示占位符。用三个占位符表示三个槽。{:^3.0f}%表示某%,[{}->{}]前者占位符表示星号*,即已阅读进度条,后者占位符表示点.,即剩余进度条。
1 | time.sleep(0.1) |
表示将程序短暂的停顿1秒
单行动态刷新
刷新的本质
刷新的本质是用后打印的字符覆盖之前的字符。
比如说,截止到2021年7月16日9点19分,国内疫情实时大数据报告有9007979480人在浏览这个网页,当我刷新一次截止到2021年7月16日9点20分,这个数据变成了9007982317,用后面的数据覆盖了原来数据的位置,之前的数据被替换,对用户来说,这就是刷新效果。
这就需要我们的程序,在输出某一个 字符的字符串的时候,不能够换行到下一行。因为一旦换行到下一行,之前的数据就不能被后来的所覆盖。因为print函数执行完后会进行到下一行,所以我们要让print不能换行。并且要让光标退回到之前的位置,实现覆盖。
总而言之,刷新要做到两点:
1.不能换行
2.要能退回
代码如下:
1 | import time |
执行结果如下图
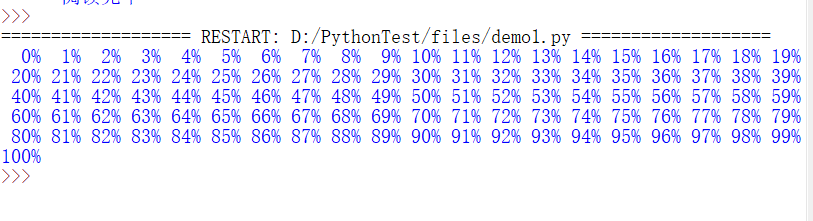
分析代码
1 | import time |
还是使用time库的sleep函数
1 | `for i in range(101):` |
构造101次的循环过程。因为为了输入文本进度条,从0%到100
%,划分为101次。
1 | print("\r{:3}%".format(i),end="") |
在format后面增加了,end="",这是print函数的一个参数,end后字符串为空字符,表示print完不会增加新的内容,光标还是停留在最后一个字符上。\r{:3}%表示在打印输出字符串之前,将光标退回到当前行的行首。
简单来说,在每次输出前,把光标放到行首,覆盖原来的数据,在输出后也不换行,下一次循环再输出的时候,再把光标放到行首,覆盖上次的数据后,再输出,又不换行。这样就构成了一种单行刷新的效果。
1 | time.sleep(0.1) |
表示将程序短暂的停顿1秒
分析结果
我们看到的是从0%到100%的结果,但实际上是一个一个覆盖刷新的效果。因为IDLE本身是一个编写式的开发环境,它并不是程序运行的主要环境。

进度条的改进完善
运用知识
1、字符串处理
2、数字处理
3、时间库的使用
1 | import time |
运行结果如下图

区别:
print("-----开始阅读------")
print("开始阅读".center(scale//2,"-"))
刚开始我们为了让结果看起来更美观,用减号-来分隔,但如果页面布局或大小变化,这样显得不太智能。现在我们使用字符串处理中的.center方法,将一个-字符填充在执行开始或者执行结束的两侧,通过填充的方式,自动实现减号构成的分隔线条。
并且我们还增加了计时效果start = time.perf_counter(),确定了一个开始时间,而dur = time.perf_counter() - start表示每次循环所消耗的时间。
print("\r:{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end="")中的\n,表示文本的刷新效果,实现光标向行首移动。end=""表示每次输出后不换行。
进度条的举一反三
计算问题扩展
文本进度条程序使用了perf_counter()计时,计时方法适合各类需要统计时间的计算问题。
在上文我们可以看到在每次打印进度条后,会加上一个时间,即相隔循环打印时间。这样我们就可以用perf_counter()来比较不同算法时间、统计部分程序运行时间。
进度条应用扩展
不仅可以应用于文本进度条,也可以在大型加载的程序中增加进度条,因为进度条是人机交互的桥梁,通过进度条我们可以直观的看到计算机运行的进度,可以给我们带来对程序更好的理解。
 wechat
wechat alipay
alipay