
RSA公钥文件解密的分析
前言
今天,手一抽打开了这个网站并注册登录
(一个早上看奥运会碌碌无为
我想就顺便试试水吧)
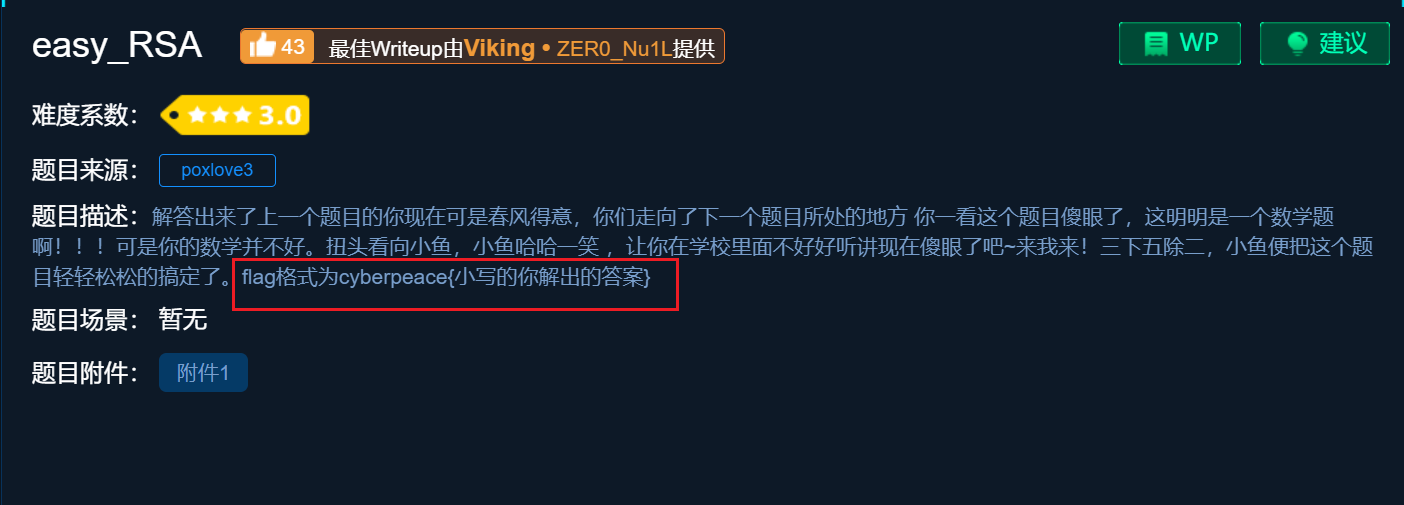
先做的是easy_RSA,已经把d算出来了,可是提交显示不对..仔细看了题目的要求后..说:flag格式为cyberpeace{小写的你解出的答案}。我以为这是把答案转化成cyberpeace格式…上网搜索“在线cyberpeace转化”未果,才知道原来答案要带上这一串英文啊..
然后,我又手一抽,点到了下一题..然鹅计时已经开始
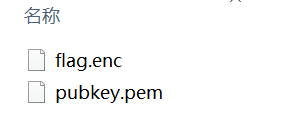

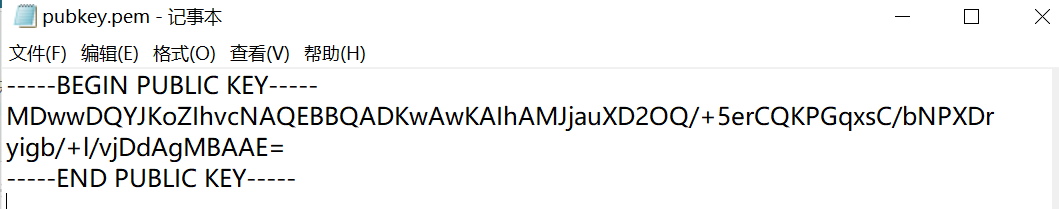
啊?都是乱码,没有n,e,c咋解呢这
于是乎,复制了BEGIN PRIVATE KEY到浏览器搜索,顺其自然地开始了我对rsa公钥文件解密的study(
解密
提n,e
这时候我们有如下的publickey.pem文件:
——-BEGIN PUBLIC KEY——-
MDwwDQYJKoZIhvcNAQEBBQADKwAwKAIhAMJjauXD2OQ/+5erCQKPGqxsC/bNPXDr
yigb/+l/vjDdAgMBAAE=
——-END PUBLIC KEY——-
现在我们需要做的就是从这段字符串中提出n和e
pem后缀
OpenSSL 使用 PEM 文件格式存储证书和密钥。PEM 实质上是 Base64 编码的二进制内容,再加上开始和结束行,如证书文件的:
1 | -----BEGIN CERTIFICATE-----` |
在这些标记外面可以有额外的信息,如编码内容的文字表示。文件是 ASCII 的,可以用任何文本编辑程序打开它们。
简单来讲,pem文件这种格式就是用于ASCII(Base64)编码的各种X.509 v3 证书。所以我们用base64解码
base64编码
从一个表格中了解base64的发展
| 名称 | 缺点 | 特点 |
|---|---|---|
| 二进制 | 长 | 简单,0和1 |
| Hex(16进制 | 不好表示文本 | |
| ASCLL码 | 只能表示英文 | 包含字符多 |
| UTF-8 | 乱码 | 兼容各种语言 |
| Base-64 | 国际化 |
用base64解码:
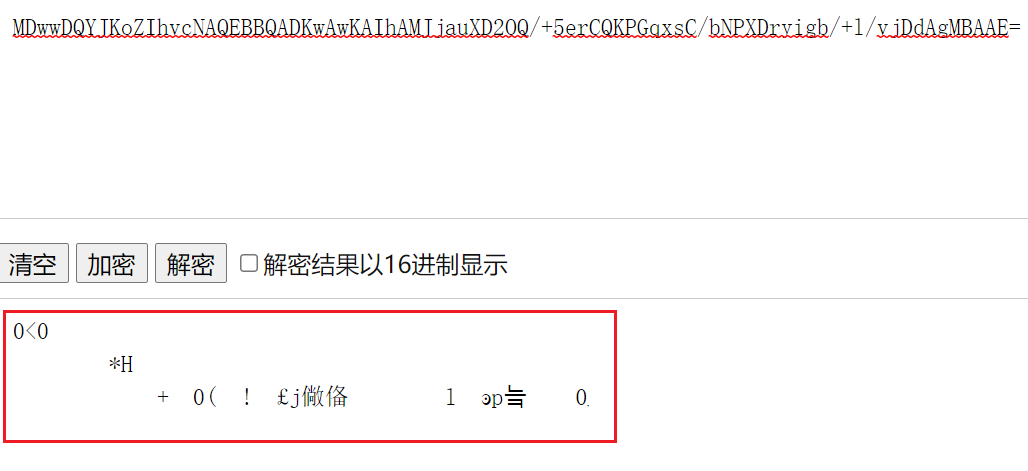
解出来是一段乱码,旁边有个可以以15进制显示的选项,我们试一下

发现结尾是”\x01\x00\x01”,猜测e=10001
再看看解码后的长度为162,我们找到偏移表,发现模数的偏移位置是159,长度是3,加起来正好162~那么说明这段字符串就是指数和模数加密过后的结果。
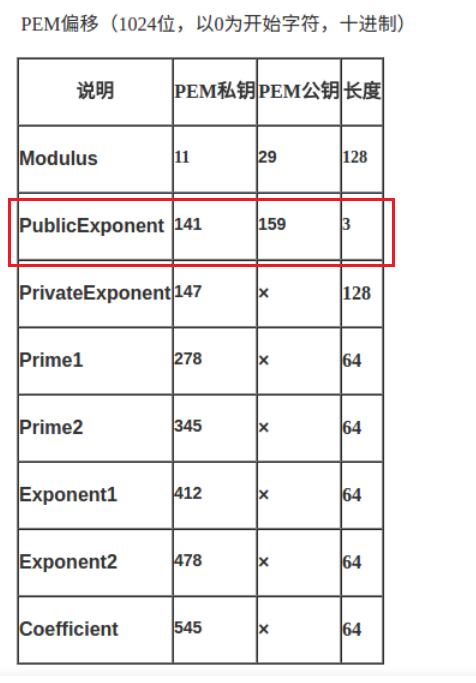
解e和n
1 | # -*- coding: utf-8 -*- |
结果如下:
1 | ('C2636AE5C3D8E43FFB97AB09028F1AAC6C0BF6CD3D70EBCA281BFFE97FBE30DD', '010001') |
这个即为我们求出来模数N和指数e
网上说可以用虚拟机Kali Linux直接用命令
1 | openssl rsa -pubin -text -modulus -in warmup -in pubkey.pem |
试了下,确实很方便
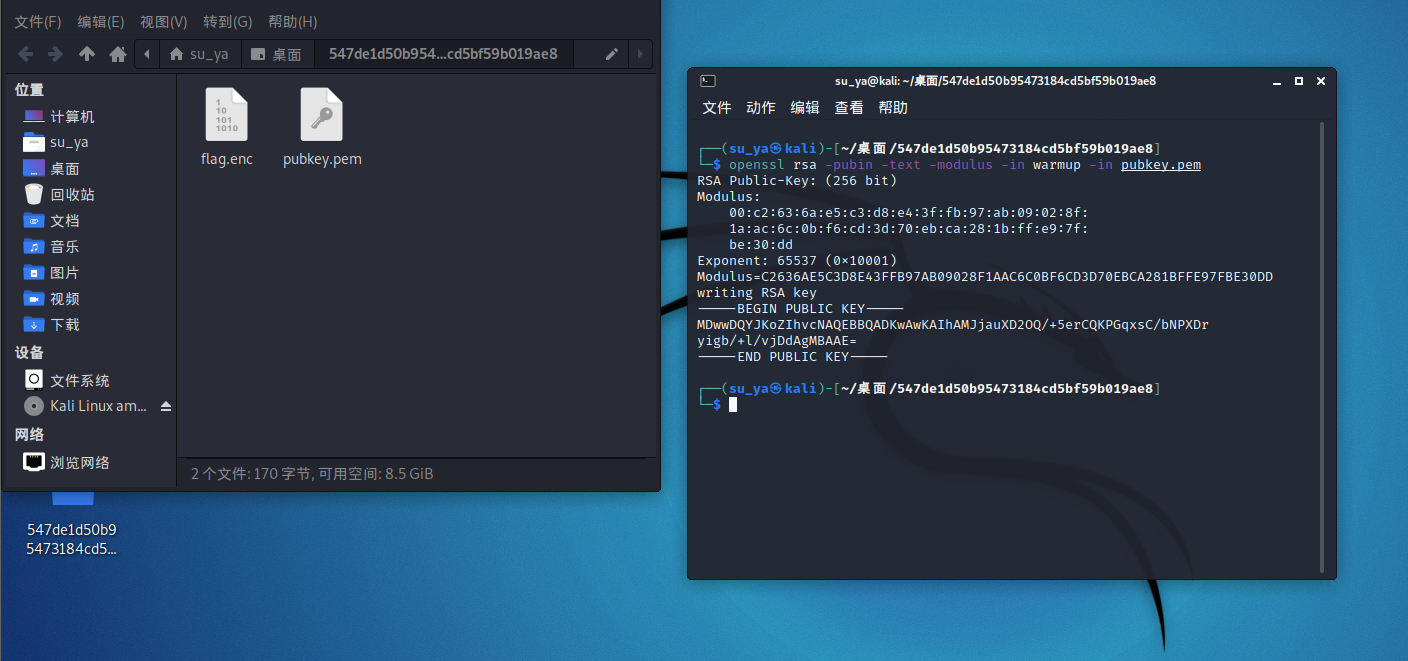
我们把n=C2636AE5C3D8E43FFB97AB09028F1AAC6C0BF6CD3D70EBCA281BFFE97FBE30DD,e=10001(十六进制)在线转化十进制

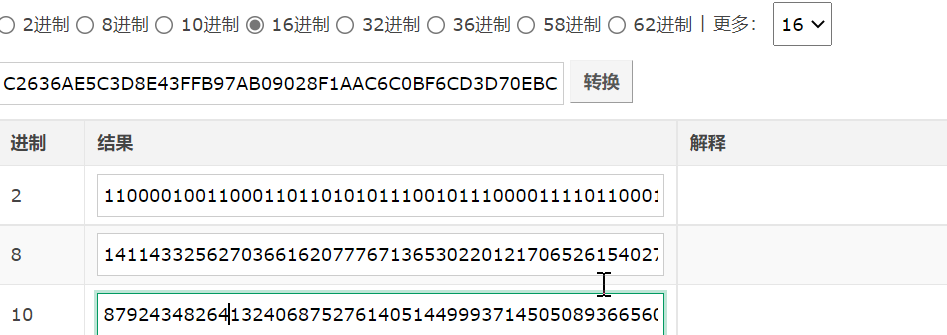
所以e=65537``n=87924348264132406875276140514499937145050893665602592992418171647042491658461
得到n,e后就是常规的做题啦
分解n得pq
解码网址上篇也有用到http://www.factordb.com/

p = 275127860351348928173285174381581152299
q = 319576316814478949870590164193048041239
求d
走个Python执行结果
1 | import gmpy2 |
结果d=10866948760844599168252082612378495977388271279679231539839049698621994994673

求m
1 | import gmpy2 |

总结
给出的文件不一定直接给出数字,有时候需要先解码(像这题),提取关键字眼,间接求数字。
有时Python比虚拟机操作繁琐。
一些编码的类型要识别出来(比如base64,hex)
能直接利用网站在线求解的不需要写Python
 wechat
wechat alipay
alipay
