
编码入门总结
前言
编码—隐匿在计算机背后的语言。在计算机眼里读到的所有文字都是由0和1组成的字符串,为了能让汉字正常显示在屏幕上,我们需要做以下两件事情:
1、给所有的汉字一个独一无二的数字编号,做一个数字编号到汉字的mapping关系(即字符集)
2、把这个数字编号能用0和1表示出来
第2件事情并不是直接把数字编号用二进制表示出来那么简单,还要处理多个字连在一起的时候如何做分隔的问题。第2件事情通常解决方案要么就是规定好每个字长度(例如所有文字都是2bytes,不够的前面用0补齐),要么就是在用0和1表示的时候,不仅需要表示出数字编码,还要暗示给计算机接下来多少个连续byte构成一个字。
进入编码
定义
编码是信息从一种形式或格式转换为另一种形式的过程。解码,是编码的逆过程。
关系
这是几种常见的中文编码之间的兼容性(子集=同时存在也不冲突=不会出现乱
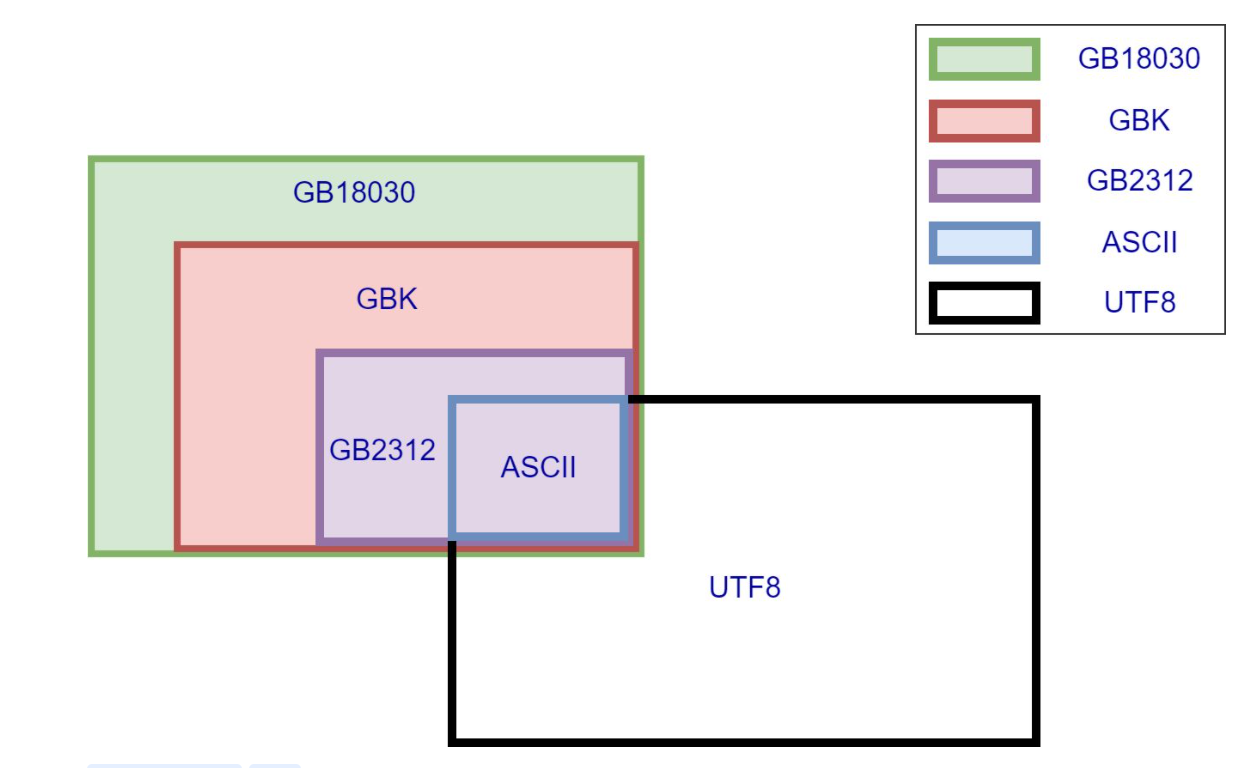
从中我们可以看到ASCLL的兼容性是最好的,而UTF-8与它部分没有交集,这也是平常会出现乱码的原因。
分类
ASCLL编码
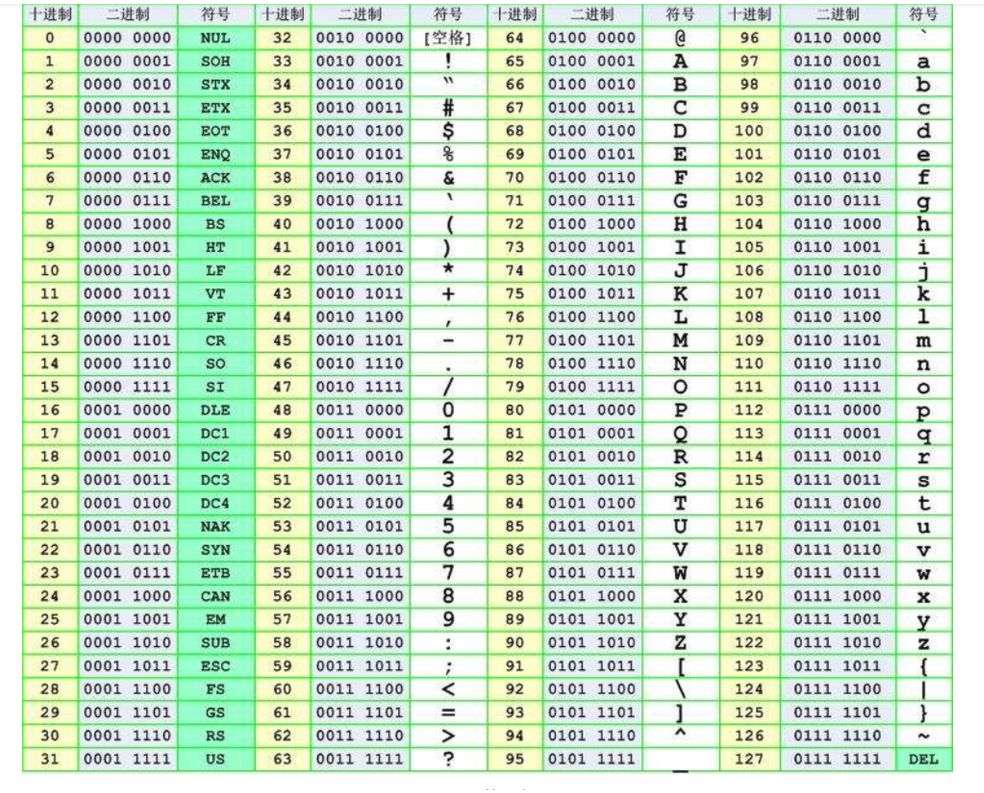
ASCII编码每个字母或符号占1byte(8bits),并且8bits的最高位是0。通常所说的标准ASCII只有前128个值!(2^7=128)
ASCLL非打印控制字符
ASCII表上的数字0–31分配给了控制字符,用于控制像打印机等一些外围设备。例如,12代表换页/新页功能。此命令指示打印机跳到下一页的开头。
ASCLL打印字符
数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。
扩展ASCLL打印字符
扩展的ASCII字符满足了对更多字符的需求。扩展的ASCII包含ASCII中已有的128个字符(数字0–32显示在下图中),又增加了128个字符,总共是256个。
GB系列编码
GB全称GuoBiao国标,GBK全称GuoBiaoKuozhan国标扩展。GB18030编码兼容GBK,GBK兼容GB2312。
GB2312
最早一版的中文编码,每个字占据2bytes。由于要和ASCII兼容,那这2bytes最高位不可以为0了(否则和ASCII会有冲突)。在GB2312中收录了6763个汉字以及682个特殊符号,已经囊括了生活中最常用的所有汉字。
GB2312编码表有个值得注意的点,这个表中也有一些数字和字母,与ASCII里面的字母非常像。例如A3B2对应的是数字2,但是ASCII里面50(十进制)对应的也是数字2。他们的区别就是输入法中所说的“半角”和“全角”。全角的数字2占两个字节。
通常,我们在打字或编程中都使用半角,即ASCII来编写数字或英文字母。
GBK
由于GB2312只有6763个汉字,我汉语博大精深,只有6763个字怎么够?于是GBK中在保证不和GB2312、ASCII冲突(即兼容GB2312和ASCII)的前提下,也用每个字占据2bytes的方式又编码了许多汉字。经过GBK编码后,可以表示的汉字达到了20902个,另有984个汉语标点符号、部首等。值得注意的是这20902个汉字还包含了繁体字
GB18030
然而,GBK的两万多字也已经无法满足我们的需求了,还有更多可能你自己从来没见过的汉字需要编码。
这时候显然只用2bytes表示一个字已经不够用了(2bytes最多只有65536种组合,然而为了和ASCII兼容,最高位不能为0就已经直接淘汰了一半的组合,只剩下3万多种组合无法满足全部汉字要求)。因此GB18030多出来的汉字使用4bytes编码。当然,为了兼容GBK,这个四字节的前两位显然不能与GBK冲突
值得一提,实际中GB18030很少提到,通常GBK见得比较多,这是因为如果你去看一下GB18030里面所编码的文字,你会发现自己一个字也不认识……
Unicode编码
Unicode是一种字符集标准,最常见的unicode字符编码是UTF-8
UTF-8与前面说的GB系列编码不兼容,所以如果一个文件中即有UTF-8编码的文字,又有GB18030编码的文字,那绝对会有乱码。
Unicode赋予了全世界所有文字和符号一个独一无二的数字编号,UTF-8所做的事情就是把这个数字编号表示出来(要处理多个字连在一起的时候如何做分隔的问题
UTF-8解决字符间分隔的方式是数二进制中最高位连续1的个数来决定这个字是几字节编码。0开头的属于单字节,和ASCII码重合,做到了兼容。
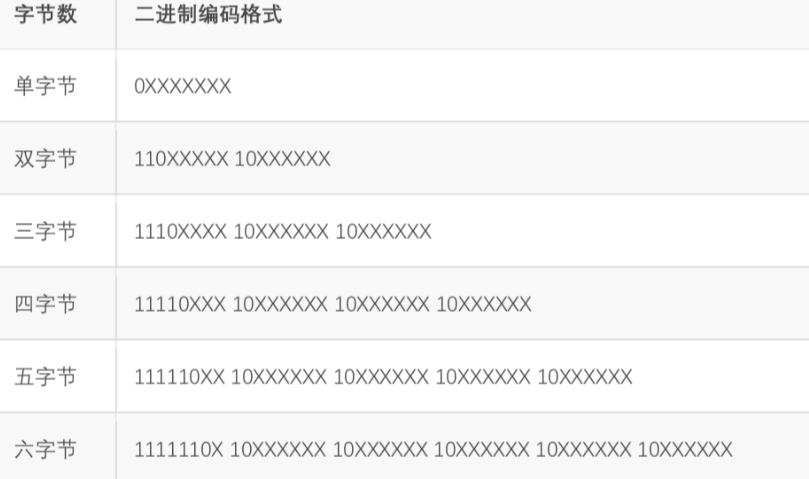
上表中标注X的位置才是真正用来表示Unicode数值的。
对于中文汉字来说,所有常用汉字的Unicode值都可以用3字节的UTF8表示出来,而GBK编码的汉字基本是2字节(GB18030虽4字节但是日常没人会写那些字)。这也就导致了,如果把GBK编码的中文文本另存为UTF8编码,体积会大50%左右。这也是UTF8的一点小瑕疵,存储同样的汉字,体积比GBK要大50%。
不过在“可表示世界上所有文字”这一巨大优势面前,UTF8的这点小瑕疵可以忽略了,所以日常开发中最常使用UTF8。
base家族
base64
特点:a-z A-Z 0-9 + / ==补位
用途:编码邮件内容、网页图片
原理:Base64将输入字符串按字节切分,取得每个字节对应的二进制值(若不足8比特则高位补0),然后将这些二进制数值串联起来,再按照6比特一组进行切分(因为2^6=64),最后一组若不足6比特则末尾补0。将每组二进制值转换成十进制,然后在表格中找到对应的符号并串联起来就是Base64编码结果。
由于二进制数据是按照8比特一组进行传输,因此Base64按照6比特一组切分的二进制数据必须是24比特的倍数(6和8的最小公倍数)。24比特就是3个字节,若原字节序列数据长度不是3的倍数时且剩下1个输入数据,则在编码结果后加2个=;若剩下2个输入数据,则在编码结果后加1个=。
Base64编码转换工具,Base64加密解密 (qqxiuzi.cn)
base32
特点:A-Z 2-7 ==补位,不区分大小写,避免了1,8,0与I,B,O的混淆
用途:一些对大小写不敏感的文件系统
原理:Base32将任意字符串按照字节进行切分,并将每个字节对应的二进制值(不足8比特高位补0)串联起来,按照5比特一组进行切分,并将每组二进制值转换成十进制来对应32个可打印字符中的一个。
由于数据的二进制传输是按照8比特一组进行(即一个字节),因此Base32按5比特切分的二进制数据必须是40比特的倍数(5和8的最小公倍数)。例如输入单字节字符“%”,它对应的二进制值是“100101”,前面补两个0变成“00100101”(二进制值不足8比特的都要在高位加0直到8比特),从左侧开始按照5比特切分成两组:“00100”和“101”,后一组不足5比特,则在末尾填充0直到5比特,变成“00100”和“10100”,这两组二进制数分别转换成十进制数,通过上述表格即可找到其对应的可打印字符“E”和“U”,但是这里只用到两组共10比特,还差30比特达到40比特,按照5比特一组还需6组,则在末尾填充6个“=”。
Base32编码解码,Base32在线转换工具 - 千千秀字 (qqxiuzi.cn)
base16
特点:非常接近hex(base16是大写,然后hex是小写,其余不变)
原理:Base16先获取输入字符串每个字节的二进制值(不足8比特在高位补0),然后将其串联进来,再按照4比特一组进行切分,将每组二进制数分别转换成十进制,在下述表格中找到对应的编码串接起来就是Base16编码。可以看到8比特数据按照4比特切分刚好是两组,所以Base16不可能用到填充符号“=”。
Base16编码后的数据量是原数据的两倍:1000比特数据需要250个字符(即 250*8=2000 比特)。换句话说:Base16使用两个ASCII字符去编码原数据中的一个字节数据。
Base16编码解码,Base16在线转换工具 - 千千秀字 (qqxiuzi.cn)
hex
特点:用0-9,A-F表示这16种情况。(十六进制
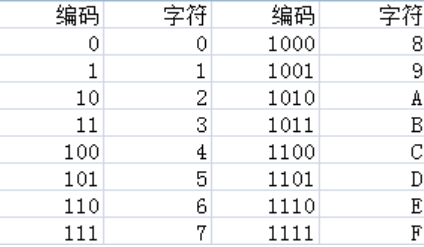
原理:编码时,将8位二进制码重新分组成两个4位的字节(8位=1字节,其中一个字节的低4位是原字节的高4位,另一个字节的低4位是原字节的低4位,其他都补0,然后输出这两个字节对应十六进制数字作为编码。
结果:Hex编码后的长度是源数据的2倍
ASCII码: A (65)
二进制码:0100_0001
重新分组:0000_0100 0000_0001
十六进制: 4 1
Hex编码:41
HTML编码
特点:以&开头,以;结尾
用途:在HTML文件中,是HTML编写过程中使用特殊的编码字符来进行网页页面的正确显示,是网页上面的一种编码格式。
1 | 编码前:& |
urlencode
特点:有%(又叫百分号编码
用途:构造反序列化对象、sql注入绕过、文件包含绕过
CTF在线工具-在线URL编码|URL解码 (ssleye.com)
1 | 编码前:欢迎来到我的博客 |
morsecode
特点:由.和-组成的代码,中间以空格或者/间隔
CTF在线工具-在线莫尔斯电码编码|在线莫尔斯电码解码|莫尔斯电码算法|Morse (ssleye.com)
1 | 编码前:欢迎来到我的博客 |
摩尔斯电码字母和数字对应表:

jsfuck
特点:仅含有+[]!()
用途:书写JavaScript代码
shellcode编码
Quoted-printable编码
特点:任何一个8位的字节值可编码为3个字符—一个等号”=”后跟随两个十六进制数字(0–9或A–F)表示该字节的数值。
Quoted-printable 可译为“可打印字符引用编码”、“使用可打印字符的编码”,我们收邮件,查看信件原始信息,经常会看到这种类型的编码!它是多用途互联网邮件扩展(MIME) 一种实现方式。其中MIME是一个互联网标准,它扩展了电子邮件标准,致力于使其能够支持非ASCII字符、二进制格式附件等多种格式的邮件消息。目前http协议中,很多采用MIME框架!quoted-printable 就是说用一些可打印常用字符,表示一个字节(8位)中所有非打印字符方法。
1 | 编码前:欢迎来到我的博客 |
网络管理员在线工具 - Quoted-Printable (mxcz.net)
XXencode编码
特点:64个字符,跟base64打印字符相比,就是UUencode多一个“-” 字符,少一个”/” 字符。
原理:XXencode将输入文本以每三个字节为单位进行编码。如果最后剩下的资料少于三个字节,不够的部份用零补齐。这三个字节共有24个Bit,以6bit为单位分为4个组,每个组以十进制来表示所出现的数值只会落在0到63之间。以所对应值的位置字符代替。它所选择的可打印字符是:+-0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz,一共64个字符。
在线XXencode编码|在线XXencode解码|XX编码|XX解码|XXencode编码原理介绍—查错网 (chacuo.net)
uuencode
特点:不含小写字母
UUencode是一种二进制到文字的编码,最早在unix 邮件系统中使用,全称:Unix-to-Unix encoding
原理:UUencode将输入文本以每3个字节为单位进行编码,如果最后剩下的资料少于三个字节,不够的部份用零补齐。三个字节共有24个Bit,以6-bit为单位分为4个组,每个组以十进制来表示所出现的字节的数值。这个数值只会落在0到63之间。然后将每个数加上32,所产生的结果刚好落在ASCII字符集中可打印字符(32-空白…95-底线)的范围之中。
1 | 编码前:欢迎来到我的博客 |
Escape/Unescape
特点:%u
原理:Escape/Unescape加密解码/编码解码,又叫%u编码,采用UTF-16BE模式。 Escape编码/加密,就是字符对应UTF-16,16进制表示方式前面加%u。Unescape解码/解密,就是去掉”%u”后,将16进制字符还原后,由utf-16转码到自己目标字符。
中文电码
特点:四个字符为一组
中文电码查询 Chinese Commercial Code - 标准电报码免费在线查询|姓名电码|美国签证电码 (mcdvisa.com)
新月佛论禅
特点:新佛曰
1 | 编码前:欢迎来到我的博客 |
生僻字
特点:生僻看不懂
汉字拼音在线转换,输入汉字查看拼音(小写、大写、首字母大写;标注声调,多音字识别) (qqxiuzi.cn)
1 | 编码前:淛匶襫黼瀬鎶 |
社会主义核心价值观编码
特点:爱过主义文明和谐等24字
社会主义核心价值观编码器 · 在线工具 - VIP (atool.vip)
1 | 编码前:欢迎你 |
 wechat
wechat alipay
alipay
