
C语言入门
数据类型包括
基本类型(以二进制补码形式存储)
- 整型
- 短整型:short-2字节
- 整型:int-4字节
- 长整型:long-4/8字节(取决于32/64位机)
- 浮点型
- 单精度-4字节
- 双精度-8字节
- 字符型
- char-1字节(存储字符ASCII值)
- 枚举类型enum
在“枚举”类型的定义中列举出所有可能的取值, 被说明为该“枚举”类型的变量取值不能超过定义的范围。该说明的是,枚举类型是一种基本数据类型,而不是一种构造类型,因为它不能再分解为任何基本类型。
枚举类型定义
1
2
3
4
5
6enum 枚举名{
枚举元素1,
枚举元素2,
...
};
enum 枚举名 枚举变量;eg
1
2
3
4
5
6
7
8
9
10enum day{
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday,
Sunday
};
enum day d;注意点
- 整型
枚举元素的值取决于定义时各枚举元素排列的先后顺序。默认情况下,第一个枚举元素的值为0,第二个为1,依次顺序加1。
1 | enum Season { |
- 构造类型
- 数组[]
存放相同类型,在内存中占用一段连续存储空间
定义数组:元素类型 数组名[元素个数]:
1 | int age[10]: |
初始化数组:
如果定义数组后,没有初始化,数组中是有值的,是随机的数
指定元素个数,完全初始化
1 | int age[3]={19,18,20}; |
不指定元素个数,完全初始化
1 | int age[]={19,18,20};//根据大括号中的元素的个数来确定数组的元素个数 |
指定元素个数,部分初始化
1 | int nums[10] = {1,2}; //没有显式初始化的元素,那么系统会自动将其初始化为0 |
注意点:
对于数组来说, 只能在定义的同时初始化多个值, 不能先定义再初始化多个值
1 | int ages[3]; |
[]中不能存放变量
1 | int number = 10; |
数组的使用
通过下标(索引)访问
1 | ages[0]=10;// 找到下标为0的元素, 赋值为10 |
数组的遍历
1 | int ages[3]={19,18,20}; |
数组的长度计算方法
数组在内存中占用的字节数取决于其存储的数据类型和数据的个数
数组所占的存储空间=一个元素所占用的存储空间*元素个数(数组的长度)
数组的长度=数组占用的总字节个数/数组元素占用的字节数
1 | int ages[3]={19,18,20}; |
二维数组
例如
1 | int a[2][3]={{1,2,3},{4,5,6}}; |
二维数组的定义
数据类型 数组名[一维数组的个数] [一维数组的元素个数]
二维数组的初始化
和一维数组类似
定义的同时初始化
1 | int a[2][3]={{1,2,3},{4,5,6}}; |
先定义后初始化
1 | int a[2][3]; |
注意点
可以省略[]内的行数,但不能省略列数。因为一旦总元素个数和列数已知,就可以推出行数
二维数组的遍历
1 | char zimu[2][3]={{'a','b','c'},{'d','e','f'}}; |
二维数组的地址
cs = &cs = &cs[0] = &cs[0][0]
- 结构体struct
用于保存一组不同类型数组的
比如:在学生登记表中,包括学生的学号,姓名,学院信息等
定义结构体类型
1 | struct 结构体名{ |
例如
1 | struct student{ |
结构体成员的访问
结构体变量名.成员名
1 | struct student{ |
结构体变量的初始化
定义的同时按顺序初始化
1 | struct student{ |
结构体数组
struct 结构体变量名称 数组名称[数组中元素个数];
定义同时初始化
1 | struct student{ |
结构体内存分析
结构体变量占用的内存空间是成员中占用内存最大成员的倍数
1 | struct student{ |
占用内存最大属性是score, 占8个字节, 所以第一次会分配8个字节
将第一次分配的8个字节分配给age4个,分配给ch1个, 还剩下3个字节
当需要分配给score时, 发现只剩下3个字节, 所以会再次开辟8个字节存储空间
一共开辟了两次8个字节空间, 所以最终p占用16个字节
- 共用体union
和结构体不同的是, 结构体的每个成员都是占用一块独立的存储空间, 而共用体所有的成员都占用同一块存储空间,由于所有属性共享同一块内存空间,所以只要其中一个属性发生了改变,其他的属性都会受到影响。
定义共用体
1 | union 共用体名{ |
- 指针类型*
指针的类型
把指针声明语句里的指针名字去掉,剩下的部分就是这个指针的类型
1 | int*ptr;//指针的类型是int* |
指针所指向的类型
把指针声明语句中的指针名字和名字左边的指针声明符*去掉,剩下的就是指针所指向的类型
1 | int*ptr;//指针的类型是int |
指针的值=指针所指向的地址=指针所指向的内存区
指针的值是xxx,即指针指向了以xxx为首地址的一片内存区域
指针指向了某块内存区域,即指针的值是某块内存区域的首地址
指针的算术运算
指针的加减是以单元为单位的(由于地址是用字节为单位的)
假设p是一个指向地址1000的整型指针,执行p++后,p将指向位置1004,因为整型是4字节,即当前位置往后移4字节。
假设p是一个指向地址1000的字符指针,执行p++后,p将指向位置1001,因为字符是1字节,下一个字符位置在1001。
指针的关系运算
指针可以用关系运算符进行比较,如==,<,>
- px > py 表示 px 指向的存储地址是否大于 py 指向的地址
- px == py 表示 px 和 py 是否指向同一个存储单元
- px == 0 和 px != 0 表示 px 是否为空指针
运算符&和*
&是取址运算符,*是间接运算符
1 | int a=12; |
1 | int *p; |
指针类型转换
当我们初始化一个指针或给一个指针赋值时,赋值号的左边是一个指针,赋值号的右边的一个指针表达式。指针所指向的类型和指针表达式所指向的类型是一样的。
1 | float f=12.3; |
强制类型转换:`(type*)type
1 | p=(int*)&f; |
这样强制类型转换的结果是一个新指针,该新指针的类型是TYPE *,它指向的类型是TYPE,它指向的地址就是原指针指向的地址。
而原来的指针p 的一切属性都没有被修改。
- 空类型(关键字void)
C语言中的void类型,代表任意类型,而不是空的意思。任意类型的意思不是说想变成谁就变成谁,而是说它的类型是未知的,是还没指定的。
void * 是void类型的指针。void类型的指针的含义是:这是一个指针变量,该指针指向一个void类型的数。void类型的数就是说这个数有可能是int,也有可能是float,也有可能是个结构体,哪种类型都有可能。
在函数的参数列表和返回值中,void代表的含义是:一个函数形参列表为void,表示这个函数调用时不需要给它传参。返回值类型是void,表示这个函数不会返回一个有意义的返回值。所以调用者也不要想着去使用该返回值。
下面是对《C语言程序设计基础》存在的一些问题解答
Q1:常见的计算机语言类型有哪些 ?
高级语言、汇编语言、机器语言
- 对比(利用3种类型语言编写1+1)
- 机器语言
10111000 00000001 00000000 00000101 00000001 00000000
- 汇编语言
MOV AX, 1 ADD AX, 1
- 高级语言
1 + 1
- 机器语言
机器语言:可以直接被cpu执行,不需要编译器
汇编语言:是机器语言的助记符,需要编译成机器语言才能执行,开始用机器语言来写第一个编译器(后面不用了)
高级语言:有了汇编语言,就可以用汇编语言来写c语言的编译器,因为麻烦接着引发出了用c语言本身来写编译器
Q2:解释器与编译器
解释器:一种计算机程序,将每个高级程序语句转换成机器代码
编译器:把高级语言编写的程序转换成机器码,将人可读的代码转换成计算机可读的01代码
两者都是将高级语言转换成机器码,解释器在程序运行时将代码转换成机器码,编译器在程序运行之前将代码转换成机器码
| 区别 | 解释器 | 编译器 |
|---|---|---|
| input | 每次读取一行 | 读取整个程序 |
| output | 不产生中间代码 | 生成中间代码 |
| 工作机制 | 编译和执行同时进行 | 先编译后执行 |
| 存储空间 | 小,因为不创建中间对象 | 大,因为生成中间目标代码 |
| 运行速度 | 慢 | 快 |
| 错误检测 | 容易,因为每次读取一行 | 难,因为是整体读取程序 |
| 编程语言 | PHP,python | C,C++,JAVA |
Q3:数据怎么存储和分类?
C程序在运行时,其代码和变量存放在内存和寄存器中,由于寄存器的个数很少,所以内存是c程序的重要存储区。变量的生存期(从系统为变量分配存储单元开始到将存储单元回收为止的期限)由变量的存储位置决定,变量的存储类型又决定了变量的存储位置。
存储空间
程序区
存放程序
静态存储区
程序开始执行时就分配的固定存储单元,如全局变量
动态存储区
在函数调用过程中进行动态分配的存储单元,如函数形参、自动变量、函数调用时的现场保护、返回值地址
存储类型
auto
自动变量,调用函数时,系统为其分配存储空间,函数执行结束,所占用的空间会被释放。必须给自动变量赋初始值。
static
静态变量,在整个程序运行期间占用存储空间不被释放,下次再调用函数时,变量的值是该函数上次调用后的值。可以不赋初始值,默认为0
register
寄存器变量,存放在cpu的寄存器中,访问寄存器的速度比访问内存中的变量速度快,因此可以存放程序中使用频率高的变量(如控制循环次数的变量),但寄存器数量有限,若超过一定数量则会自动转化为自动变量
extern
外部变量,定义在函数外部的全局变量,存放在静态存储区中
Q4:二进制是怎么编码的?
原码反码补码
计算机只能识别0和1, 所以计算机中存储的数据都是以0和1的形式存储的
数据在计算机内部是以补码的形式储存的, 所有数据的运算都是以补码进行的
二进制的最高位我们称之为符号位, 最高位是0代表是一个正数, 最高位是1代表是一个负数
正数的原码、反码和补码
正数的原码、反码和补码都是它的二进制
例如: 12的原码、反码和补码分别为1
2
30000 0000 0000 0000 0000 0000 0000 1100
0000 0000 0000 0000 0000 0000 0000 1100
0000 0000 0000 0000 0000 0000 0000 1100负数的原码、反码和补码
负数的原码:是将该负数的二进制最高位变为1
负数的反码: 是将该数的原码除了符号位以外的其它位取反
负数的补码: 就是它的反码 + 1
例如: -12的原码、反码和补码分别为1
2
3
40000 0000 0000 0000 0000 0000 0000 1100 // 12二进制
1000 0000 0000 0000 0000 0000 0000 1100 // -12原码
1111 1111 1111 1111 1111 1111 1111 0011 // -12反码
1111 1111 1111 1111 1111 1111 1111 0100 // -12补码
Q5:字符与字符串的区别?
字符是位于单撇号中的字符变量
char类型变量占1个字节存储空间,共8位
除单个字符以外, C语言的的转义字符也可以利用char类型存储
| 字符 | 意义 |
| —— | ————————————————- |
| \b | 退格(BS)当前位置向后回退一个字符 |
| \r | 回车(CR),将当前位置移至本行开头 |
| \n | 换行(LF),将当前位置移至下一行开头 |
| \t | 水平制表(HT),跳到下一个 TAB 位置 |
| \0 | 用于表示字符串的结束标记 |
|\| 代表一个反斜线字符 |
| \“ | 代表一个双引号字符” |
| \’ | 代表一个单引号字符’ |计算机只能识别0和1, 所以char类型存储数据并不是存储一个字符, 而是将字符转换为0和1之后再存储,在ASCII表中定义了每一个字符对应的整数
char类型占一个字节, 一个中文字符占3字节(unicode表),所以char不可以存储中文
char类型存储字符时会先查找对应的ASCII码值, 存储的是ASCII值, 所以字符6和数字6存储的内容不同
1
2char ch1 = '6'; // 存储的是ASCII码 64
char ch2 = 6; // 存储的是数字 6
字符串是位于双引号中的字符序列
- 在C语言中没有专门的字符串变量,通常用一个字符数组来存放一个字符串。
- 当把一个字符串存入一个数组时,会把结束符‘\0’存入数组,并以此作为该字符串是否结束的标志
- 字符串在内存中是逐个字符存储的,一个字符占用一个字节,所以字符串的结束符长度也是占用的内存单元的字节数。
Q6:signed和unsigned的区别?
signed int等价于signed,unsigned int等价于unsigned
signed和unsigned的区别:就是它们的最高位是否要当做符号位,并不会像short和long那样改变数据的长度,即所占的字节数。
- signed:表示有符号,也就是说最高位要当做符号位。但是int的最高位本来就是符号位,因此signed和int是一样的。signed的取值范围是-2^31 ~ 2^31 - 1
- unsigned:表示无符号,也就是说最高位并不当做符号位,所以不包括负数。取值范围是0 ~ 2^32 - 1。
Q7:怎么理解内存、内存地址、寻址空间?
- 内存
与内存相对的是外存,外存通常是磁性介质或光盘,像硬盘,软盘,磁带,CD等,能长期保存信息。程序和数据平常存储在硬盘等存储器上,不管你开机或关机了,它们都是存在的,不会丢失。硬盘可以存储的东西很多,但其传输数据的速度较慢。所以需要运行程序或打开数据时,这些数据必须从硬盘等存储器上先传到另一种容量小但速度快得多的存储器,之后才送入CPU进行执行处理。这中间的存储器就是内存。
它们要存储数据,所以就必须按一定的单位的数据分配一个地址。有了地址,程序才能找到这些数据。
- 内存地址
计算机把所有的信息都给数字化了,所以它知道自已把一个数据,一条命令记到了内存中的哪个(些)位置。
如果让计算机在内存里记住“丁小明”这个名字,可以示意为:

第一行,每一格表示一段内存,而格子里的内容是这段内容记下的数据;
第二行,每一格内数字就是对应的内存的地址。
汉字在一个地址(位置),必须放在连续的两个地址空间内。像英文的里字母,比如’A’, 像阿拉伯数字:比如’1’,可以就是放在一个内存地址里。
计算机记住“丁”字的内存地址是首地址,也就是1000H
但在计算机中,所有信息都被数字化为二进制的0和1,那“丁”字的内存地址1000H该怎么存储呢
我们假设在那一串里的 0001 0010 0111 0101 对应的是 “丁” 字,那么有:
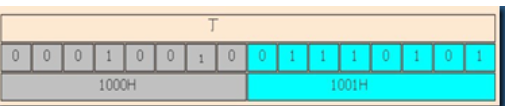
第一行,“丁”是给人看的
第二行, 0001 0010 0111 0101是计算机内存中实际存储的数据
第三行,1000H和1001H是内存的地址,每8个0,1分为一格地址
即1字节=8比特,内存地址存的是字节而不是比特
位,称为比特,即0或1,是计算机存储的最小单位
字节是计算机中数据处理的基本单位(内存机构的最小寻址单位)
- 寻址空间
一般指的是CPU对于内存寻址的能力。通俗地说,就是能最多用到多少内存的一个问题。数据在存储器(RAM)中存放是有规律的 ,CPU在运算的时候需要把数据提取出来就需要知道数据存放在哪里 ,这时候就需要挨家挨户的找,这就叫做寻址,但如果地址太多超出了CPU的能力范围,CPU就无法找到数据了。 CPU最大能查找多大范围的地址叫做寻址能力 ,CPU的寻址能力以字节为单位 ,如32位寻址的CPU可以寻址2的32次方大小的地址也就是4G,这也是为什么32位的CPU最大能搭配4G内存的原因 ,再多的话CPU就找不到了。
参考 内存地址的概念和理解_
内存地址与内存空间 - Lan_ht - 博客园 (cnblogs.com)
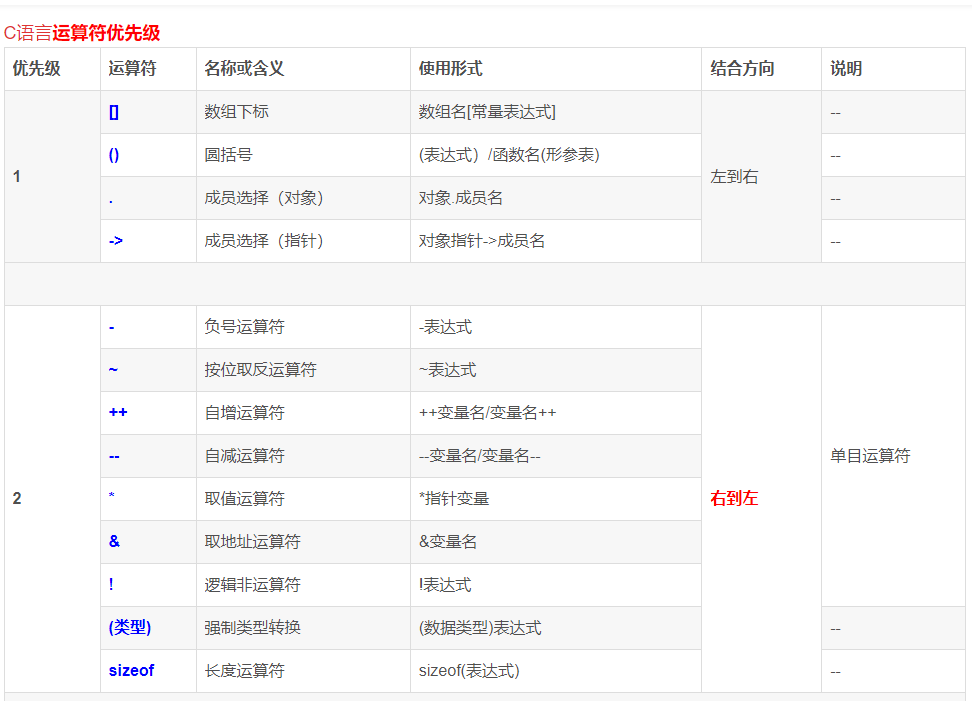
Q8:运算顺序的规则以及短路求值
按照连接运算对象的个数,可以分为单目运算,双目运算,三目运算。
| 名称 | 特点 | 运算方向 |
|---|---|---|
| 单目运算符 | 只带一个运算对象 | 自右向左 |
| 双目运算符 | 带两个运算对象 | 自左向右 |
| 三目运算符 | 条件运算符 | 自左向右 |
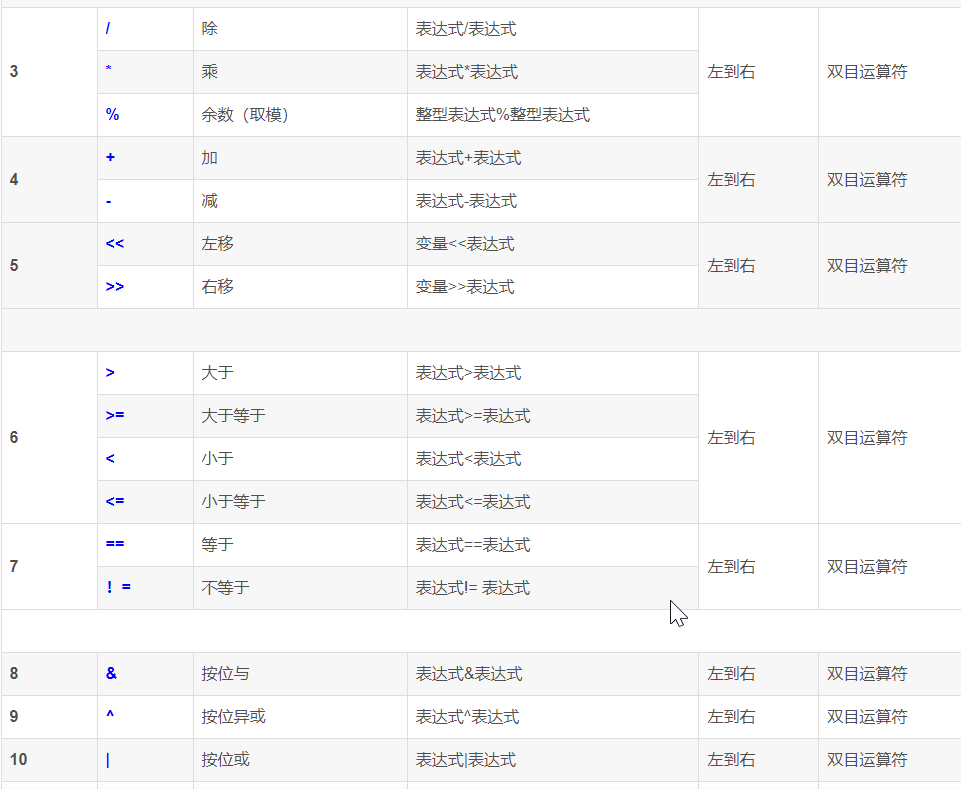
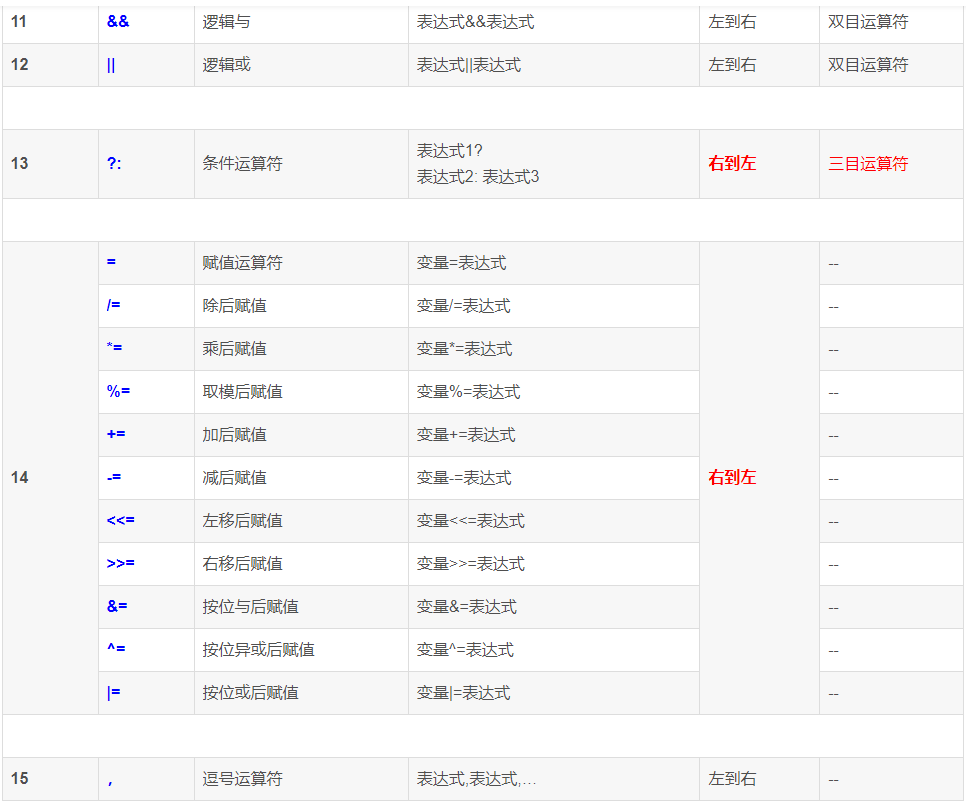
运算优先级:单目运算符>双目运算符>三目运算符>赋值运算符>逗号运算符
短路求值
C语言的逻辑操作符 && , || 具有 短路求值 的特性。
- 逻辑与 &&
&& 操作符的左操作数总是首先进行求值, 如果它的值为真, 则继续计算右操作数的值, 然后执行与操作得到表达式结果; 如果它的值为假, 根据与操作 有假则假 的性质可以断定该表达式的值为假, 所以不再计算右操作数的值. - 逻辑或 ||
|| 操作符的左操作数也是首先进行求值, 如果它的值为假, 则继续计算右操作数的值, 然后执行与操作得到表达式结果; 如果它的值为真, 根据或操作 有真则真 的性质可以断定该表达式的值为真, 所以不再计算右操作数的值
1 | #include <stdio.h> |
则输出结果
1 | a=3,b=5 |
若是
1 | #include <stdio.h> |
则输出结果
1 | a=1,b=5 |
 wechat
wechat alipay
alipay